机器学习-白板推导 5 降维
机器学习-白板推导 5 降维
1. 降维 Dimension Reduction
机器学习中,最关心的是泛化误差,降低泛化误差是非常关键的。泛化误差和过拟合等关系图如下
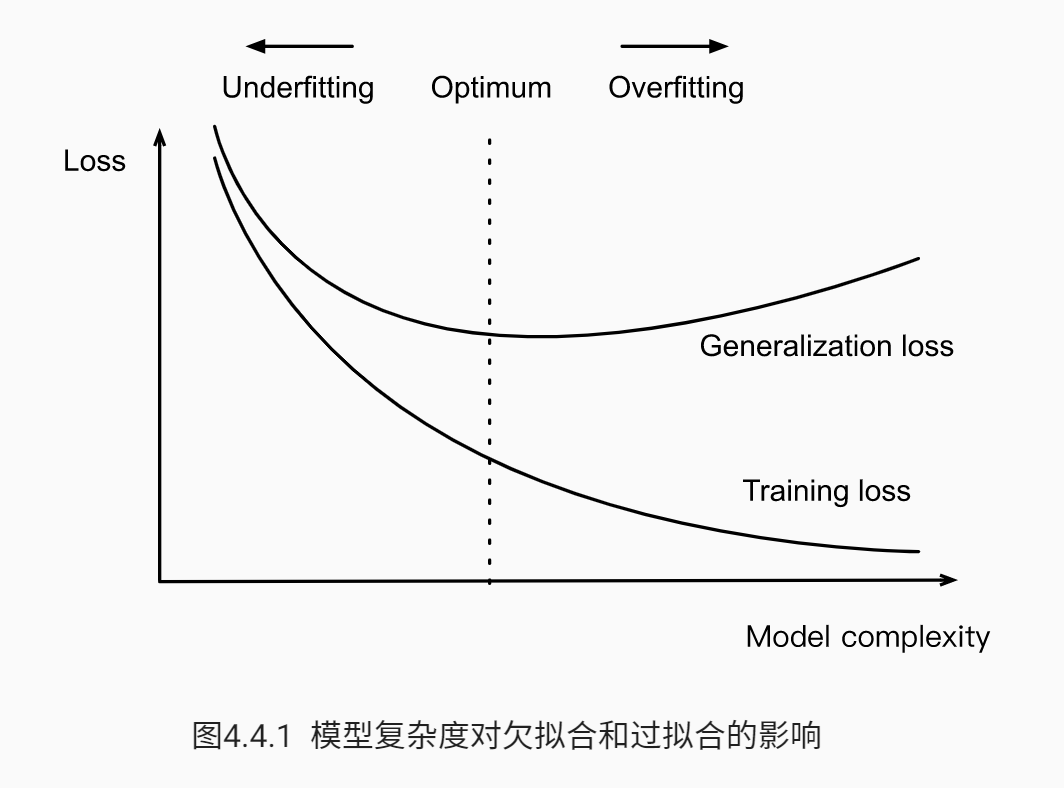
解决过拟合的方法有:
- 增加数据量
- 正则化,如Lasso和Ridge本质都是降维,Lasso会让部分趋于0,来消除一些特征。
- 降维
维度灾难:
高纬度有更大的特征空间,需要更多数据才可以拟合模型。若特征是二值的,则每增加一个特征,数据列都在以2的指数级增长,更何况很多特征不是二值的
几何角度:
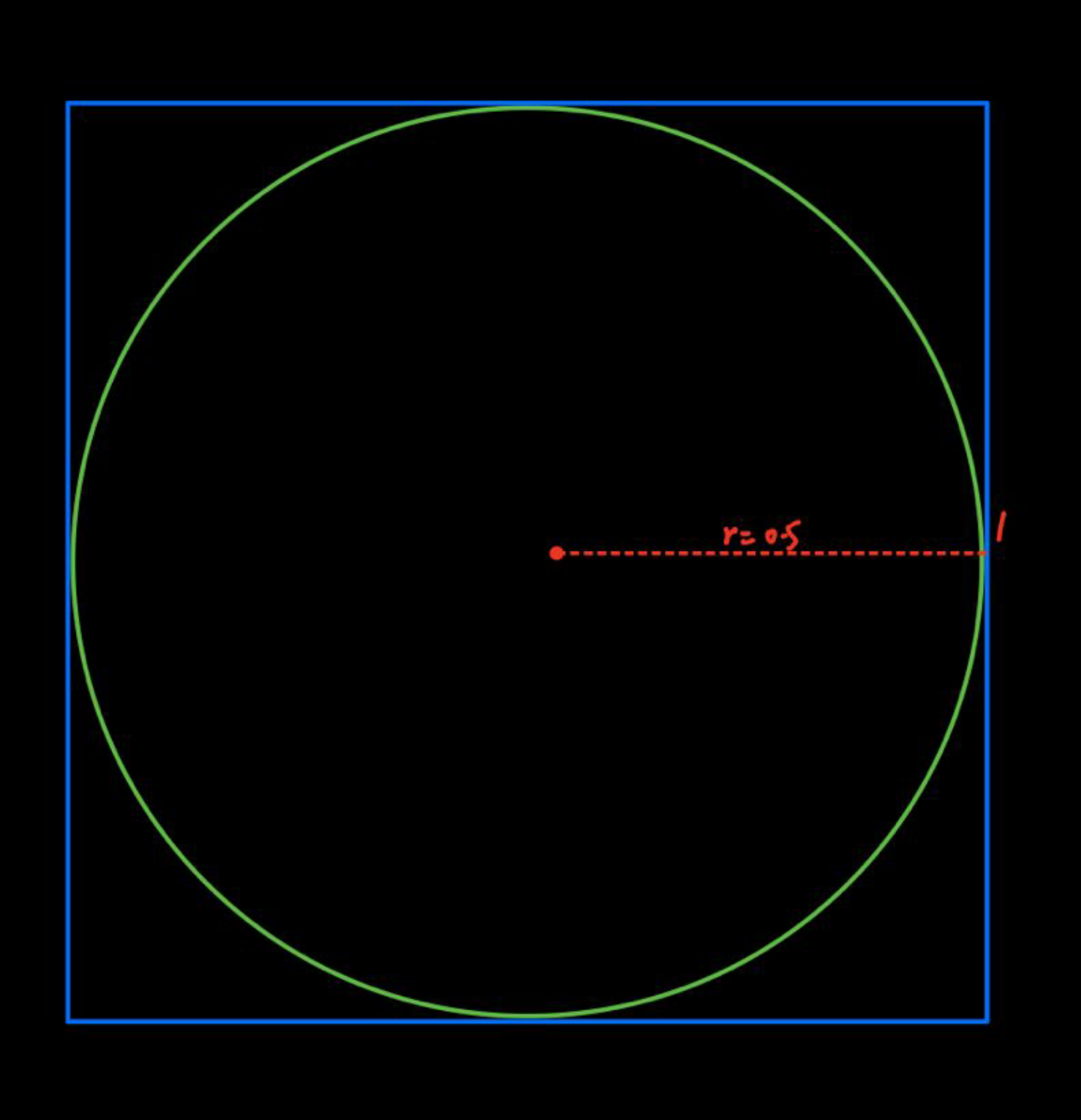
- 如下图所示,假定正方形边长为1,则其内切圆半径为0.5,正方形面积为1,圆面积为。拓展到3维时,正方形体积为1,内切球体积为。
如下图所示,假设外圆半径为,则内圆半径为。在高维情况下,外圆体积为, 中间圆环体积为。
那么有:

从两个例子可以看出,高维情况下,数据占据着空间表明,内部趋于0,数据分布稀疏。
常用的降维方法:
- 直接降维:特征选择,将不重要的特征扔掉
- 线性降维:PCA, MDS(multidimensional scaling)
- 非线性降维:流形(将数据嵌入到高维空间),局部线性嵌入
2. 样本均值和方差的矩阵表示
后续PCA和SVD都是在矩阵上操作,所以先将均值和方差矩阵表示。
假设数据集为:
其中。
其样本均值为:
样本方差为:
对式1, 2简化表示:
1. 均值
其中, 。
2. 方差
其中,
而,叫做 centering matrxi。并且有 ,那么式4进一步化简得:
3. PCA
PCA基本思想是将所有数据投影到一个子空间取,从而达到降维的目的。这个子空间要满足:
- 最大可分性:样本点在这个超平面上的投影尽可能分开,所有数据在子空间中更为分散。
- 最近重构性:样本点到这个平面的距离足够近,那么损失的信息最少,即在补空间上的分量小。
关键思想:
- 一个中心:将原始特征空间重构,将线性相关的特征转化为线性无关的特征。
- 两个基本点:最大投影方差和最小重构距离.
如下图所示,将原始数据分别投影到,在方向更为分散,因而选择往这个方向投影。

PCA降维步骤:
- 数据去中心化 ,就是减去均值,一定得去中心化。
- 投影到一个新的方向上,这个新的方向就是重构的特征空间的坐标轴,并且要满足投影后得到的数据的方差最大,即最大投影方差,这样同时也保证了数据重构的距离最小。
4. 最大投影方差理解PCA
假设投影方向为, 并且将其模设为1,,那么原数据去中心化后的数据在方向上的投影为,又因为去中心化后均值为0,所以投影方差为。
那么目标函数为:
其中是协方差矩阵。
使用拉格朗日乘子法:
对求导得:
其中是协方差矩阵,是特征值,是特征向量。那么只要将协方差矩阵S进行特征值分解,将求得的特征值排序,取需要的前p个,在计算出对应的特征向量,就是PCA的解。
5. 最小重构距离理解PCA
去中心化后数据为, 假设我们将其投影到对应空间后,取前p个特征有:
假定已经按照特征值从大到小排列。
那么目标函数为(去中心数据点到投影点的距离最小),本质上源空间有p个特征,如果降维后选取了q个特征,降维的数据也就是舍弃掉第q+1到第p这几个方向上的信息。
式10跟式7一样有:
这里为协方差矩阵的前k个特征向量。
6. SVD角度看PCA
SVD介绍,如果我们先对数据去中心化,左乘中心矩阵H(在上面第3部分),然后进行SVD分解,因此有:
其中,
- 是的矩阵,并且 。
- 是的矩阵,并且 。
- 为的矩阵,且是对角阵。
式5中, 因此:
那么是的特征值分解,是特征值矩阵。
若我们构造矩阵如下:
将进行特征分解后得到主成分,将投影到主成分的方向后,其坐标为
而直接对进行特征分解,坐标矩阵, 这种方法叫主坐标分析 PCoA ——Principle Coordinate Analysis。
原因: , (就是将式14代入),那么有,这里 是特征值, 就是坐标。
T分解和S分解的区别:
- 是的矩阵, 是的矩阵
- 当数据量较少是或特征数较多时用PCoA
Inference
[1] 降维
[2] 主成分分析
 wechat
wechat alipay
alipay




